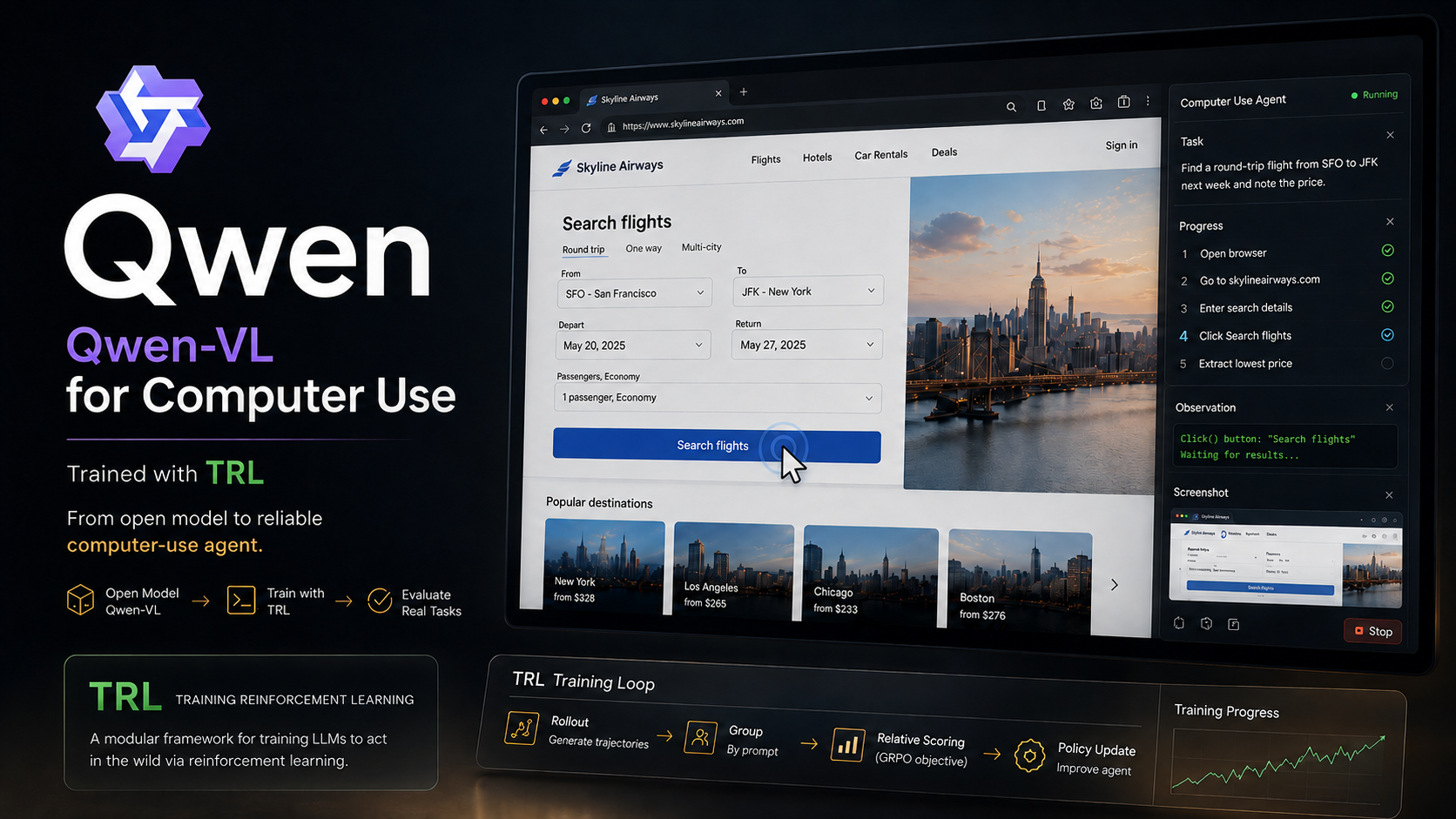
The Agent That Looks at the Screen
For most of their short history, software agents have been polite guests in other people’s houses. They acted through doors that someone built for them on purpose: REST APIs, function schemas, accessibility trees, the DOM. If the door existed, the agent could walk through it. If it didn’t, the agent was stuck on the porch.
Computer-use models break that habit. Instead of asking an application for a structured handle on itself, the model looks at the screen (the actual rendered pixels a person would see) and acts on it the way a person does: move the cursor here, click, type, scroll, look again. When Anthropic shipped computer use and OpenAI shipped Operator, this stopped being a research demo and became a product category. The pitch is enormous: an agent that can drive any software, on any operating system, with no integration and no permission from the application, because it is simply using the interface the way you do.
Strip away the planning and the multi-step choreography in those demos and you reach a single, unglamorous skill that all of it is built on. Given a screenshot and an instruction in plain English (“open the settings menu”), put the cursor on the right pixel. That’s it. That skill has a name: visual grounding. Get it reliably right and the flashy agent becomes possible. Get it wrong and every plan above it collapses, because a perfect chain of reasoning that ends in a click on the wrong button is just a confident mistake.
This post is about teaching that one skill to a small, open model, Qwen2.5-VL-3B (Apache-2.0), from a standing start, for about the price of lunch. The whole project ran on a single rented 24 GB GPU and cost roughly $15. It is also a chance to watch the ideas this blog has covered one at a time finally snap together into something that does a job: quantization is what lets a multi-billion-parameter model train on a hobbyist’s card; memory-efficient attention is what lets it read a dense, high-resolution screenshot at all; and GRPO is the reinforcement-learning algorithm that does the final polishing. None of these are new here. What’s new is assembling them into a working computer-use agent.
Two techniques did the teaching, in sequence: supervised fine-tuning, then reinforcement learning. The headline, which I’ll defend with numbers rather than vibes: SFT did almost all of the heavy lifting, and RL earned its keep in a narrower, more interesting way than the hype suggests.
What “Computer Use” Is, and Why Grounding Is the Keystone
It helps to be precise about scope, because “computer-use agent” covers a huge range of ambition.
At the hard end is full task execution: “book me the cheapest flight to Tokyo next month.” That requires a live environment, long-horizon planning, recovery from mistakes, and credit assignment across dozens of steps where only the final outcome tells you whether you succeeded. It is genuinely hard, and benchmarks like OSWorld and WebArena exist to measure it. It is also expensive and slow to train against, because every rollout needs a real, stateful machine on the other end.
At the tractable end is grounding, a single step: screenshot plus instruction in, one coordinate out. It needs no simulator. The reward is something you can compute with arithmetic, did the predicted point land inside the target element’s bounding box?, rather than something a learned judge has to decide. And it is exactly the slice the recent GUI reinforcement-learning literature (UI-R1, GUI-R1, GTA1) converged on, precisely because it is the most learnable, verifiable piece of the problem. Grounding is the keystone: it is the smallest unit of “use the computer” that you can train, measure, and trust on its own.
So that is the task. Concretely, the model is handed an image and one line of text, and must answer with a pixel:
Visual Grounding: Screenshot + Instruction → Click
The whole task in one widget. Toggle a training stage; watch where the model clicks.
The reward is as blunt as it looks in that widget. The model proposes $(x, y)$; we check whether that point falls inside the ground-truth box; it scores 1 if it does and 0 if it doesn’t. No partial credit, no geometry beyond a containment test. Hold onto that simplicity. It turns out to be the quiet hero of the reinforcement-learning stage later.
Why Grounding Is Hard, and the Architecture Choice It Forces
The naive way to make a vision-language model output coordinates is to treat the numbers as text. Show it a screenshot, ask for the location, and let it generate the string x=523, y=217 token by token, the same way it would generate any other text.
This works astonishingly badly, and the reason is worth sitting with. The model’s vision encoder turns the screenshot into a grid of visual tokens, each carrying a positional embedding, a sense of where on the image it lives. But the language head emits ordinary number tokens. Nothing in the architecture connects “this patch is two-thirds of the way across the screen” to “the digits five-two-three.” The model has to learn that mapping implicitly, from examples, with no built-in bridge between visual position and textual coordinate. Train it on 1080p screenshots and it tends to fail on a 4K monitor, because the implicit mapping it memorized doesn’t transfer to coordinate ranges it never saw. Grounding looks like a perception problem; a lot of it is actually a coordinate-representation problem.
The field has two answers. The first, used by models like Microsoft’s Florence-2, is to normalize coordinates into an abstract 0–1000 grid, so the model never sees absolute pixels and learns relative position instead. The second, used by Qwen2.5-VL, is to lean into absolute scale: its multimodal rotary position embeddings (MRoPE) and native dynamic-resolution processing let it represent boxes and points in the real pixel coordinates of the original image, at whatever size that image happens to be. This gives a much tighter coupling between what the vision encoder sees and what the language head says, which is precisely the alignment grounding lives or dies on.
That property is the main reason Qwen2.5-VL-3B is the base model here, and the de-facto backbone of the GUI-RL literature. It is small enough to fine-tune on one consumer-grade card, permissively licensed, and, crucially, it already grounds reasonably well out of the box, so there is real signal for training to amplify rather than a blank slate to fill.
There’s a cost to that native-resolution superpower, though, and it shapes every practical decision downstream. A vision transformer cuts an image into patches and turns each into a token; the bigger the image, the more tokens, and attention cost grows with the token count. For Qwen2.5-VL the rule of thumb is roughly
$$\text{visual tokens} \approx \frac{H \times W}{28 \times 28},$$so a modest screenshot is already hundreds of tokens and a large one is well over a thousand. Slide the resolution and watch what happens to the bill:
One Screenshot, How Many Tokens?
A vision transformer cuts the image into patches. More pixels, more tokens, more memory.
This is why every serious training run pins a min_pixels/max_pixels budget and why high-resolution screenshots are the number-one cause of out-of-memory crashes. It is also why memory-efficient attention matters here as much as it does for long-context text: reading a screen is a long-context problem, just in two dimensions. (On the actual run, the attention backend was PyTorch’s SDPA rather than a hand-rolled FlashAttention kernel, but the principle from the Flash Attention post is exactly what keeps thousands of image-patch tokens tractable.)
Why a Hobbyist Can Do This for $15
A 3-billion-parameter model in full precision is about 6 GB just to store, and full fine-tuning needs several multiples of that for gradients, optimizer state, and activations. Add a thousand-token screenshot’s worth of activations on top and a 24 GB card is hopeless. The reason this project fits at all is a stack of compression tricks, each of which this blog has covered before and which here finally pull their weight together.
LoRA freezes the pre-trained weights entirely and learns a small, low-rank update alongside them, typically a fraction of a percent of the parameters. You are no longer training the model; you are training a thin adapter that nudges it. Memory for optimizer state and gradients collapses accordingly, and as a bonus the frozen base can’t catastrophically forget what it already knew.
QLoRA takes it further: it stores the frozen base in 4-bit precision (the information-theoretically-tuned NF4 format) and trains the bf16 adapter on top. The base weights are quantized for storage and dequantized on the fly for computation. That storage-vs-compute split is the whole trick, and it’s the same machinery covered in the quantization deep-dive. A 3B model that wouldn’t fit for full fine-tuning now loads in a handful of gigabytes with room to spare for rollouts.
The rest is good housekeeping that keeps the run on one card: gradient checkpointing (recompute activations in the backward pass instead of storing them), an 8-bit optimizer (quantize the optimizer state too), gradient accumulation (simulate a big batch with many small ones), and a capped pixel budget (fewer visual tokens, less memory).
On the hardware side, 24 GB is the magic number: the largest you can rent cheaply and still call commodity. The choice comes down to two generations of the same class of card:
| GPU | Architecture | VRAM | ~On-demand | ~Spot |
|---|---|---|---|---|
A10G (g5.xlarge) | Ampere | 24 GB | ~$1.00/hr | ~$0.40/hr |
L4 (g6.xlarge) | Ada Lovelace | 24 GB | ~$0.80/hr | ~$0.30/hr |
The L4’s newer Ada Lovelace architecture has better native support for the BF16 and FP8 math that quantized fine-tuning leans on. Pleasantly, it’s also the cheaper of the two. This project ran on a g6.2xlarge (one L4, a bit more host CPU and RAM for data prep) at roughly $1/hr on-demand, in us-east-1. Across baseline evaluation, the SFT run, the GRPO run, and the inevitable re-runs, the whole thing came to about $12–15 of GPU time. Spot pricing or the smaller xlarge would have shaved it further. The point is not the exact figure; it’s that the entry barrier to actually doing this is now a takeout dinner, not a research grant.
The Recipe: SFT First, Then GRPO, and the Insight That Makes RL Worth It
With the base model chosen and the memory math solved, the training itself is two stages.
Stage one is supervised fine-tuning. Take a few thousand examples of (screenshot, instruction, correct coordinate), and train the model, through its LoRA adapter, to reproduce the answer. The objective is plain next-token cross-entropy on the response only. SFT does two jobs extraordinarily well: it locks the output format so the model reliably emits a clean {"x": int, "y": int} and nothing else, and it installs a strong behavioral prior: the sense that “close button” means top-corner, that toolbar icons cluster along an edge, that a labeled control is where its label is.
It does both jobs fast. On this run the cross-entropy collapsed from 4.36 to 0.57 in the first thirty steps and then essentially flatlined; the model had learned the task (format and prior together) almost immediately, and the remaining 120 steps were polish.
SFT Learns the Task in ~30 Steps
Cross-entropy loss and token accuracy across the 150-step run (logged every 10 steps).
But the way we set SFT up carries a subtle flaw, and it is the hinge of this whole story. The training label is a single coordinate, the center of the target box. Cross-entropy punishes the model for predicting anything else, which means it is being trained to hit one exact pixel. Yet the actual task does not care about that pixel at all. Any click inside the button works. SFT is optimizing a needlessly strict objective: it trains the model to reproduce one exact pixel, nagging it toward a precision the task never asked for, with no way to express “anywhere in this region is fine.” None of this is a law of supervised learning; it falls out of the label we chose, and sampling targets from across the box instead of its center would blunt it.
Reinforcement learning closes the same gap more directly. As the GTA1 work on GUI grounding put it, SFT “rigidly trains the model to predict the exact center of the target element,” whereas a reward-driven approach can “reward any click that falls within the target element region.” Swap the strict imitation loss for a reward that returns 1 for any point inside the box, and the model stops chasing one pixel and starts treating the whole target as correct.
SFT Imitates One Pixel; RL Rewards the Whole Target
Drag the click. Watch how each objective scores the exact same spot.
That is the conceptual reason to add RL on top of SFT, and it predicts something specific that we’ll see in the numbers: RL should matter most exactly where SFT’s center-point rigidity costs the most, on small, awkward targets where “near the center” and “inside the box” are very different bets.
GRPO and the Verifiable Reward
The reinforcement-learning algorithm is GRPO (Group Relative Policy Optimization), which I covered in depth in From RLHF to GRPO, so here’s only the part that matters for grounding. For each prompt you sample a group of $G$ candidate answers, score each one, and use the group’s own statistics as the baseline:
$$\hat{A}_i = \frac{r_i - \text{mean}(r_1, \dots, r_G)}{\text{std}(r_1, \dots, r_G)}.$$Answers above the group average get reinforced, answers below get suppressed, and the standard deviation normalizes the scale. The elegance is that there is no separate value network (the group is the baseline), which is precisely what makes GRPO cheap enough to run alongside a quantized model on one 24 GB card.
The reward is where grounding gets to show off. There is no learned reward model, no human preference data, no judge that can be gamed. The reward is a deterministic geometry check, the same point_in_box test from the widget at the top of this post, and it has a property most reward functions only dream of: it is identical to the evaluation metric. When your training reward is the thing you ultimately measure, the usual gap between “what we optimized” and “what we wanted” disappears, and there is nothing to reward-hack. This is the paradigm called RLVR (Reinforcement Learning with Verifiable Rewards), the same idea behind DeepSeek-R1 and Tülu 3, where correctness is checked by a function rather than judged by a model. A small format reward rides along to keep the output parseable, weighted low so it can’t dominate:
The hyperparameters came almost verbatim from the GTA1 recipe, which had already mapped this terrain: a group size of $G = 8$, a tiny learning rate of $10^{-6}$, no chain-of-thought (“thinking” doesn’t help pure grounding and costs tokens), and no KL penalty to a reference policy ($\beta = 0$, which lets the coordinates move freely). One constraint deserves a callout because it shaped the whole run: GRPO’s reward signal vanishes if the batch is too small. With only a handful of samples per update, the group statistics are too noisy to learn from and the model collapses. The fix is a large effective batch, reached here by accumulating gradients to 128 completions per update. On a single GPU you don’t get that batch for free; you get it by accumulating patiently.
On the tooling: of the libraries that implement RL for vision-language models, Hugging Face TRL’s GRPOTrainer is the one that realistically fits a single 24 GB card. The alternatives (EasyR1, VLM-R1, verl) are excellent but assume a multi-GPU cluster. That single fact quietly decided the stack.
What Actually Happened
Time for numbers. The benchmark is ScreenSpot-v2: 1,272 real screenshot-instruction pairs across iOS, Android, macOS, Windows, and the web, scored by point-in-box accuracy. Three checkpoints: the untouched model, after SFT, and after GRPO.
What Moved the Needle
ScreenSpot-v2 · 1,272 samples · point-in-box accuracy
Read the bars in order. Zero-shot, the base model gets 71.3%, already not bad, which is exactly why it’s a good base. SFT lifts that to 82.2%, a +10.8-point jump, and it does so uniformly across every platform while closing the model’s worst weakness: icons, which have no text label to latch onto, climb from 63.0% to 74.2%. Just as telling, the number of completely unparseable outputs went from 15 at zero-shot to zero after SFT. That is the format lock and the behavioral prior earning their keep. SFT is the heavy lifting, full stop.
Then GRPO. On ScreenSpot-v2 the gain is small: a slight edge on the matched evaluation, with text accuracy ticking up to 89.7%. And here is the honest, useful part: that small gain is exactly what the theory predicts. ScreenSpot-v2 is a comparatively easy, near-saturated benchmark; once SFT has the model clicking inside the right box most of the time, there isn’t much headroom left for “aim better” to harvest. The center-point rigidity that RL fixes simply doesn’t cost much when the targets are large and well-labeled.
Even at much larger scale the easy benchmark behaves the same way. GTA1, training this recipe on bigger models, reports ScreenSpot-v2 climbing from 90.2 to 92.4 with GRPO: a couple of points, no more. A near-saturated benchmark simply doesn’t leave reinforcement learning much to win.
So the honest read of what we measured is this: SFT did the work, and GRPO mostly confirmed it. The place a metric-matching reward should actually earn its keep is harder grounding, the tiny targets in dense, professional UIs where landing inside the box and landing near its center finally come apart. Measuring that cleanly is the obvious next step, and the one I’d want in hand before claiming RL moved the needle.
Closing the Loop: From One Click to an Agent
A grounding model is a function: pixels and text in, one coordinate out. An agent is that function in a loop, wired to a real machine.
From One Click to an Agent
The grounding model is the eyes and the hand. The loop is the rest of the body.
Each turn: capture a screenshot, send it with the standing instruction to the model, parse the predicted box or point, reduce a box to a click target with the obvious arithmetic ($x_c = (x_1 + x_2)/2$, $y_c = (y_1 + y_2)/2$), execute the click through an OS-level driver like PyAutoGUI or Playwright, then capture the new screen and go again until the goal is met. The grounding model is the eyes and the hand; the loop is the rest of the body.
This is also where the stakes become real, and the references this project drew on are emphatic about it: a model with unconstrained control of a real screen is a security surface, not a toy. The standard mitigations are not optional. Run the agent inside an ephemeral, sandboxed virtual machine, and restrict its network egress to an allowlist of domains it actually needs. An agent that can click anything can also click the wrong thing, confidently, very fast. The grounding accuracy we spent this whole post chasing is, among other things, a safety property.
Lessons
A few things generalize well beyond this particular model.
Scope to the verifiable slice first. The temptation with computer use is to chase full autonomy immediately. Grounding is the piece you can train, measure, and trust on its own, and everything ambitious is built on it. Earn the keystone before you build the arch.
SFT imitates one pixel; RL rewards the whole target. Supervised fine-tuning installs the format and the behavioral prior, and it does the overwhelming majority of the work: here, +10.8 points in an hour. The rigidity it leaves behind, imitating a single labeled pixel, isn’t a limitation of SFT itself; it’s an artifact of how we set it up: training on the box center with a token-level loss. You could blunt it on the SFT side too, by sampling labels from across the target. RL simply takes the more direct route: reward any in-box click and you optimize the metric itself. That correction only shows up where the rigidity was costing you, which means RL’s visible payoff lives on the hard examples, not the easy benchmark.
A reward that is your metric is the cheapest cheat code there is. Point-in-box can’t be reward-hacked because there is no gap between it and the thing you actually measure. When you can phrase your objective as a deterministic check, do. Verifiable rewards sidestep an entire category of failure that learned reward models invite.
Evaluate on your training distribution. This one bit during the run: the RL model trained on images letterboxed to a fixed canvas, and evaluating it on differently-shaped images understated its score until the protocols were matched. A model can only be fairly judged on the distribution it was trained for; a mismatched eval will lie to you.
The theory has become a budget line. Quantization, memory-efficient attention, low-rank adaptation, group-relative RL: the pieces this blog has explained one at a time are now mature enough that assembling them into a working vision agent costs about $15 and an afternoon. The frontier of understanding each technique is still deep; the frontier of using all of them together has dropped to the floor. That’s the quietly remarkable part.
Try It Yourself
The full training code (data preparation, the SFT and GRPO scripts, the reward functions, the evaluation harness, and the exact config files for every hyperparameter mentioned here) is open source at the repository below. The recipe is small enough to read in an evening: one base model, one cleaned grounding dataset, a LoRA SFT pass, and a GRPO pass with a geometry-check reward.
Reproduce it: Qwen2.5-VL-3B-Instruct ·
Salesforce/grounding_dataset(≈6k for SFT, ≈1.2k prompts for GRPO) · one 24 GB GPU (NVIDIA L4) · LoRA SFT (r=16, α=32, lr 1e-4, 150 steps) then QLoRA GRPO (G=8, β=0, lr 1e-6, point-in-box + format reward, 150 steps) · evaluate on ScreenSpot-v2. Total cost ≈ $15.Repository: github.com/MdJawad/computer-use
If you read the GRPO post for the algorithm and the quantization post for the compression, this is what they look like pointed at a real, slightly stubborn problem: a small model that, after an hour of supervised teaching and a couple of hours of reinforcement, will look at a screen it has never seen and put the cursor where you asked.
Get new posts by email
Deep dives on LLM systems — inference, attention, agents, quantization — straight to your inbox. No spam, unsubscribe anytime.
Prefer a feed reader? Subscribe via RSS.