Imagine if every time you wanted to build something with LEGOs, you had to start from scratch—even when building similar structures. That’s essentially how we’ve been managing KV caches in production LLMs. Until now.
The 328GB Elephant in the Room
Here’s what nobody tells you about serving long-context LLMs: that impressive 128K context window your model supports? It’s basically unusable in production. Not because of compute limitations, but because of a memory crisis hiding in plain sight.
Let me show you the brutal math for Llama 3 70B:
| Context Length | KV Cache Size | % of Model Weights | Reality Check |
|---|---|---|---|
| 8K tokens | 21 GB | 15% | Fits on one GPU |
| 32K tokens | 84 GB | 60% | Exceeds H100 capacity |
| 128K tokens | 328 GB | 234% | Needs 4+ H100s (!!) |
That’s right—the KV cache for a single 128K-context request requires more memory than the entire model weights. Four times more. This is why most production deployments silently cap contexts at 8-16K tokens, leaving those impressive context capabilities as nothing more than marketing numbers.
The Wasteful Status Quo
Traditional serving engines treat KV caches like disposable napkins: use once, throw away. Every time you:
- Continue a conversation → Recompute the entire chat history
- Process a common document in RAG → Recompute from scratch
- Use the same system prompt → Recompute yet again
It’s like demolishing your LEGO castle every time you want to add a tower. Wasteful? Absolutely. Necessary? Not anymore.
Enter LMCache: a system that fundamentally reimagines KV caches not as temporary computational byproducts, but as reusable, composable knowledge blocks—like LEGOs for your model’s attention memory.
[Diagram 1: Traditional vs LMCache approach]
The Core Insight: Knowledge Should Be Reusable
LMCache operates on a simple but powerful principle:
“Prefill each text only once.”
Think of it like a Content Delivery Network (CDN), but instead of caching static website assets, you’re caching computed attention patterns. Just as Netflix doesn’t re-encode the same movie for every viewer, why should we recompute the same document’s KV cache for every user?
This isn’t just clever engineering—it’s a fundamental shift in how we think about LLM memory. And it’s made possible by three breakthrough innovations that each solve a seemingly impossible problem.
Innovation #1: CacheGen – Compression That Beats Physics
The Problem: Moving 328GB of KV cache from GPU to CPU should be impossible without killing performance. The PCIe bus delivers 64 GB/s while GPU memory delivers 3,000 GB/s—a crushing 47× bottleneck.
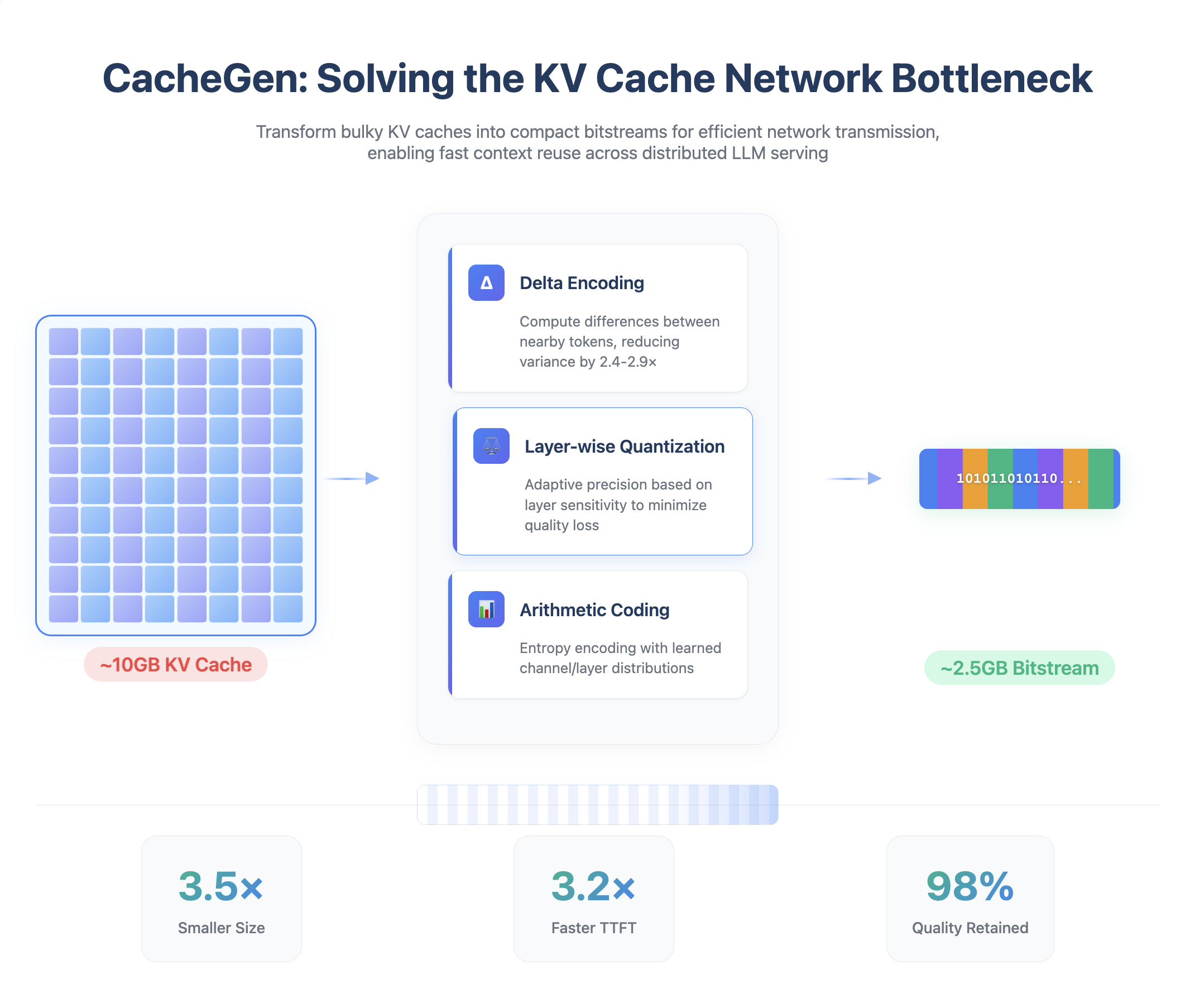
The Solution: CacheGen doesn’t try to beat the bandwidth limit—it sidesteps it entirely with purpose-built compression that understands the unique structure of KV cache data.
Here’s the clever part: KV cache tensors aren’t random data. They have patterns:
- Layers have personalities: Some transformer layers are robust to compression, others are sensitive. CacheGen profiles each layer and applies custom quantization—aggressive where it can be, gentle where it must be.
- Local correlation is high: Adjacent values often differ by small amounts. Delta encoding stores just the differences, slashing storage needs.
- GPUs are parallel beasts: Instead of decompressing on the CPU (creating a new bottleneck), custom CUDA kernels decompress directly on the GPU using massive parallelism.
The result? That impossible 328GB transfer becomes a manageable 76GB—a 4.3× reduction that makes PCIe viable without sacrificing inference speed.
[Diagram 3: CacheGen pipeline]
Innovation #2: CacheBlend – The LEGO Magic
The Problem: Traditional caching is rigid. It only works for exact prefixes—like having LEGO blocks that only stick together in one specific order.
Consider a typical RAG prompt:
[System Prompt] + [Retrieved Doc A] + [Retrieved Doc B] + [User Query]
Even if you’ve cached Doc A and Doc B separately, you can’t reuse them. Why? Because attention is positional—Doc A’s KV values depend on everything before it. When it follows a system prompt instead of appearing first, its entire attention pattern changes. Naive concatenation produces garbage.
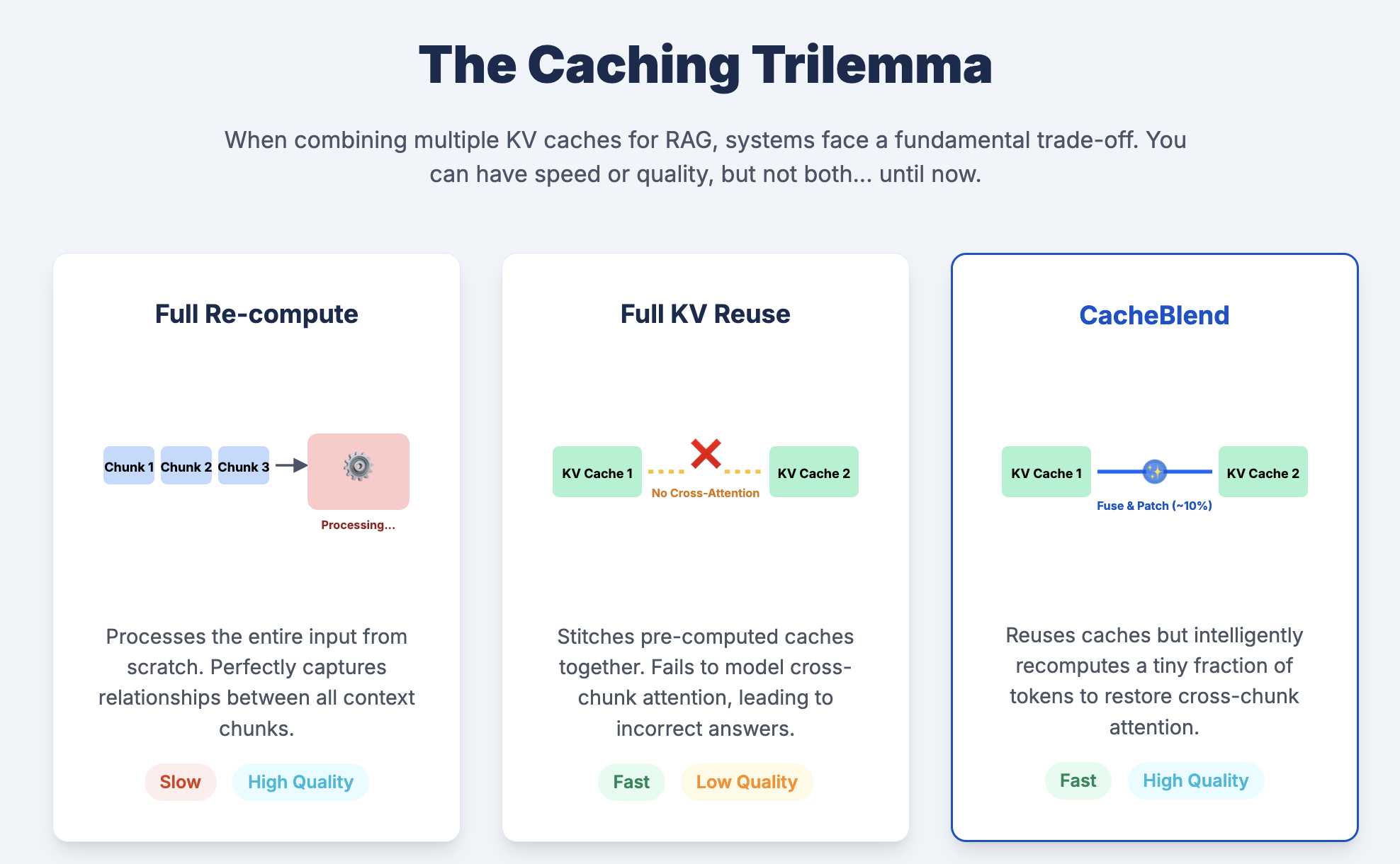
The Solution: CacheBlend makes KV caches truly composable—like LEGO blocks that intelligently adapt to their neighbors.
The key insight: when you move a cached chunk to a new position, most tokens (∼90%) barely change. Only a small subset—the “high-deviation tokens”—need updating. CacheBlend:
- Identifies the 10% that matter: Uses attention analysis to find tokens whose KV values would change most
- Surgically updates just those tokens: Recomputes only the high-deviation subset
- Blends the updates: Fuses new values with the original cache
This transforms rigid, prefix-only caching into flexible, LEGO-like composition. Same cached blocks, infinite arrangements.
[Diagram 5: CacheBlend LEGO composition]
Innovation #3: Hierarchical Memory – The Full Stack
The Problem: Even with compression, you can’t fit everything in GPU memory. You need a bigger house for your LEGOs.
The Solution: LMCache implements a complete memory hierarchy, treating GPU, CPU, and SSD as a unified pool—just like modern CPUs treat L1, L2, L3 caches and RAM.
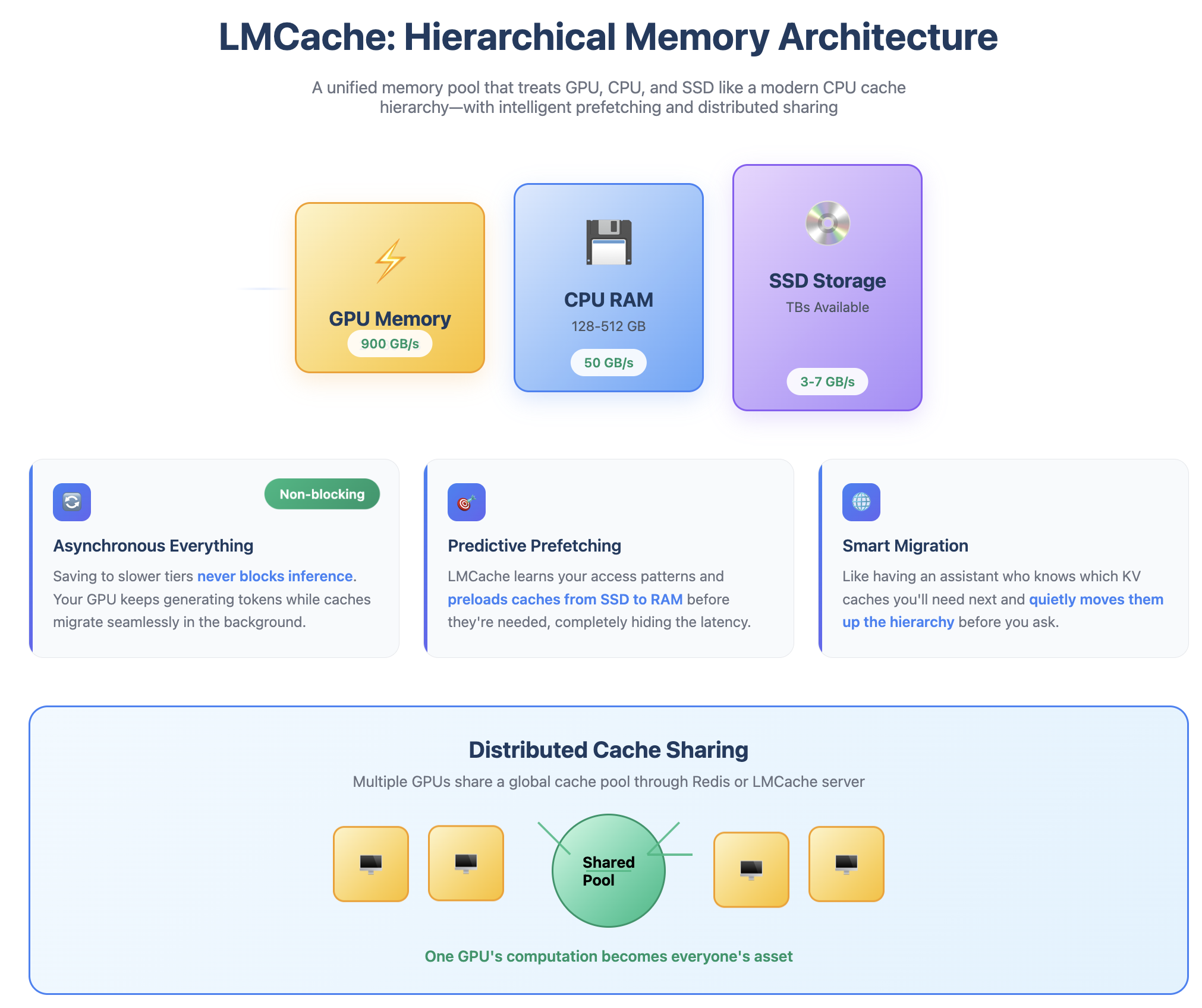
But here’s what makes it brilliant:
- Asynchronous everything: Saving to slower tiers never blocks inference. Your GPU keeps generating while caches migrate in the background.
- Predictive prefetching: LMCache learns access patterns and preloads caches from SSD to RAM before they’re needed, hiding the latency.
- Distributed sharing: Through Redis or LMCache’s server, multiple GPUs share a global cache pool. One GPU’s computation becomes everyone’s asset.
It’s like having a smart assistant who knows which LEGO sets you’ll need next and quietly moves them from the basement to your desk before you ask.
Real-World Impact: From Painful to Practical
The numbers speak for themselves:
| Scenario | Without LMCache | With LMCache | Speedup | User Experience |
|---|---|---|---|---|
| 25K token conversation | 28 seconds | 3.7 seconds | 7.7× | ☠️ → 😊 |
| RAG with 4 documents | 13 seconds | 3.6 seconds | 3.6× | 😔 → 😊 |
These aren’t incremental improvements—they’re the difference between “users abandon your product” and “users love your product.”
Playing Nice with Others: The PagedAttention Synergy
A common question: doesn’t vLLM’s PagedAttention already solve memory problems?
Not quite. They’re complementary pieces of the same puzzle:
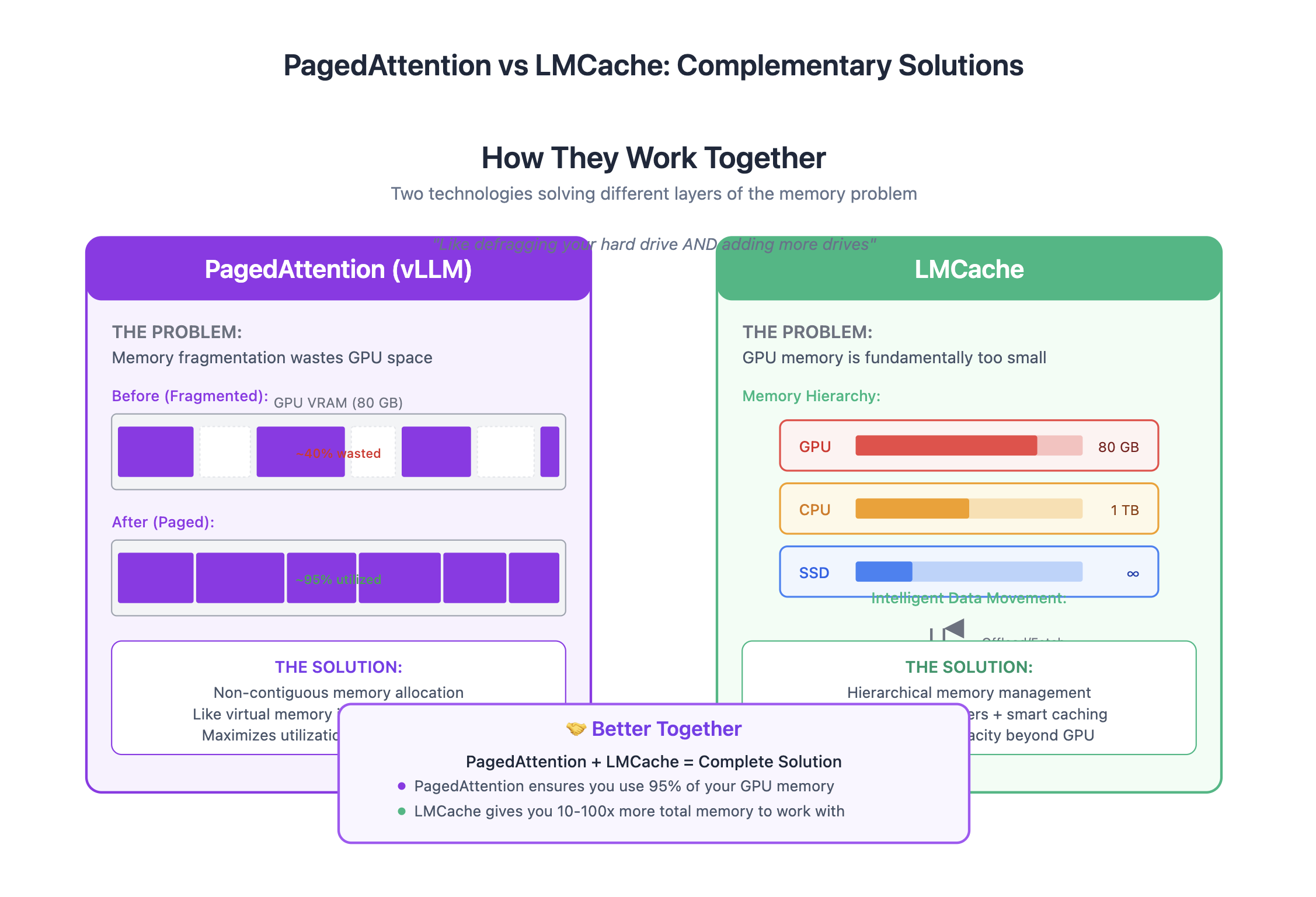
- PagedAttention: Solves fragmentation within GPU memory (like defragging your hard drive)
- LMCache: Extends total memory across tiers (like adding more hard drives)
Together, they form a complete memory management stack—PagedAttention ensures efficient packing, LMCache provides infinite capacity.
The Bigger Picture: A New Era of LLM Infrastructure
We’re witnessing a fundamental shift in what limits LLM deployment:
| Era | Bottleneck | Solution |
|---|---|---|
| 2020-2022 | Raw compute | Better GPUs, optimized kernels |
| 2022-2023 | Memory fragmentation | PagedAttention |
| 2024+ | Total memory capacity | Hierarchical caching (LMCache) |
The future isn’t just about making models bigger—it’s about making them remember intelligently. LMCache represents a paradigm shift: from treating KV cache as disposable waste to managing it as valuable, reusable knowledge.
What This Means for You
If you’re running production LLMs, LMCache changes the game:
- Those 128K context windows become actually usable – not just marketing specs
- Multi-turn conversations become affordable – no more recomputing entire histories
- RAG at scale becomes practical – cache once, reuse everywhere
- GPU costs drop dramatically – same hardware, 7× more throughput
The best part? LMCache integrates seamlessly with vLLM. It’s not a replacement—it’s an upgrade.
The LEGO Future
LMCache shows us what modern LLM serving should look like: modular, composable, and intelligent. Just as LEGO blocks revolutionized construction toys by making everything reusable and composable, LMCache is doing the same for LLM memory.
We’re moving from a world where every inference request starts from scratch to one where computed knowledge accumulates, persists, and compounds. It’s not just an optimization—it’s an architectural revolution.
The question isn’t whether you need hierarchical KV caching. It’s whether you can afford to keep throwing away 90% of your GPU’s work. In a world where every millisecond and every GB matters, the answer is clear.
Welcome to the era of composable AI memory. Time to start building.
References
- CacheBlend: Yao, J., Li, H., Liu, Y., Ray, S., Cheng, Y., Zhang, Q., Du, K., Lu, S., & Jiang, J. (2024). CACHEBLEND: Fast Large Language Model Serving for RAG with Cached Knowledge Fusion. arXiv preprint arXiv:2405.16444.
- CacheGen: Liu, Y., Li, H., Du, K., Yao, J., Cheng, Y., Huang, Y., Lu, S., Maire, M., Hoffmann, H., Holtzman, A., & Jiang, J. (2023). CacheGen: Fast Context Loading for Language Model Applications. arXiv preprint arXiv:2310.07240.
- PagedAttention (vLLM): Kwon, W., Li, Z., Zhuang, S., Sheng, Y., Zheng, L., Yu, C. H., Gonzalez, J., Zhang, H., & Stoica, I. (2023). Efficient Memory Management for Large Language Model Serving with PagedAttention. arXiv preprint arXiv:2309.06180.
- LMCache Project: The official GitHub repository for the LMCache system, including implementations of CacheGen and CacheBlend.
- vLLM Project: The official GitHub repository for the vLLM serving engine, which LMCache integrates with.