A first-principles derivation of how diffusion models work. Why the forward process has a closed form, why the reverse posterior is tractable only when conditioned on the clean image, how a page of variational bound collapses into one squared error, why the noise predictor is secretly a score function, and how that becomes Stable Diffusion.
The Policy Engine Is the Ceiling: Authorization for Agents That Do Things
An agent can be trusted with exactly as much authority as your policy engine can scope, enforce, and afterwards prove. Which makes authorization not the tax you pay to ship agents, but the thing that decides how much power they can ever be given. A deep dive into PDP/PEP architecture, Cedar and Rego, partial evaluation, workload identity, and why the credential an agent presents should be minted for the action rather than held for the deployment.

Guide, Never Solve: Teaching Hermes to Tutor Tamil
My son was using chatbots to finish his homework instead of learning from it. So I built him a tutor on a network-caged agent platform: one that guides instead of answers, reads his Tamil worksheets, runs scheduled drills, and is safe by architecture rather than by prompt.
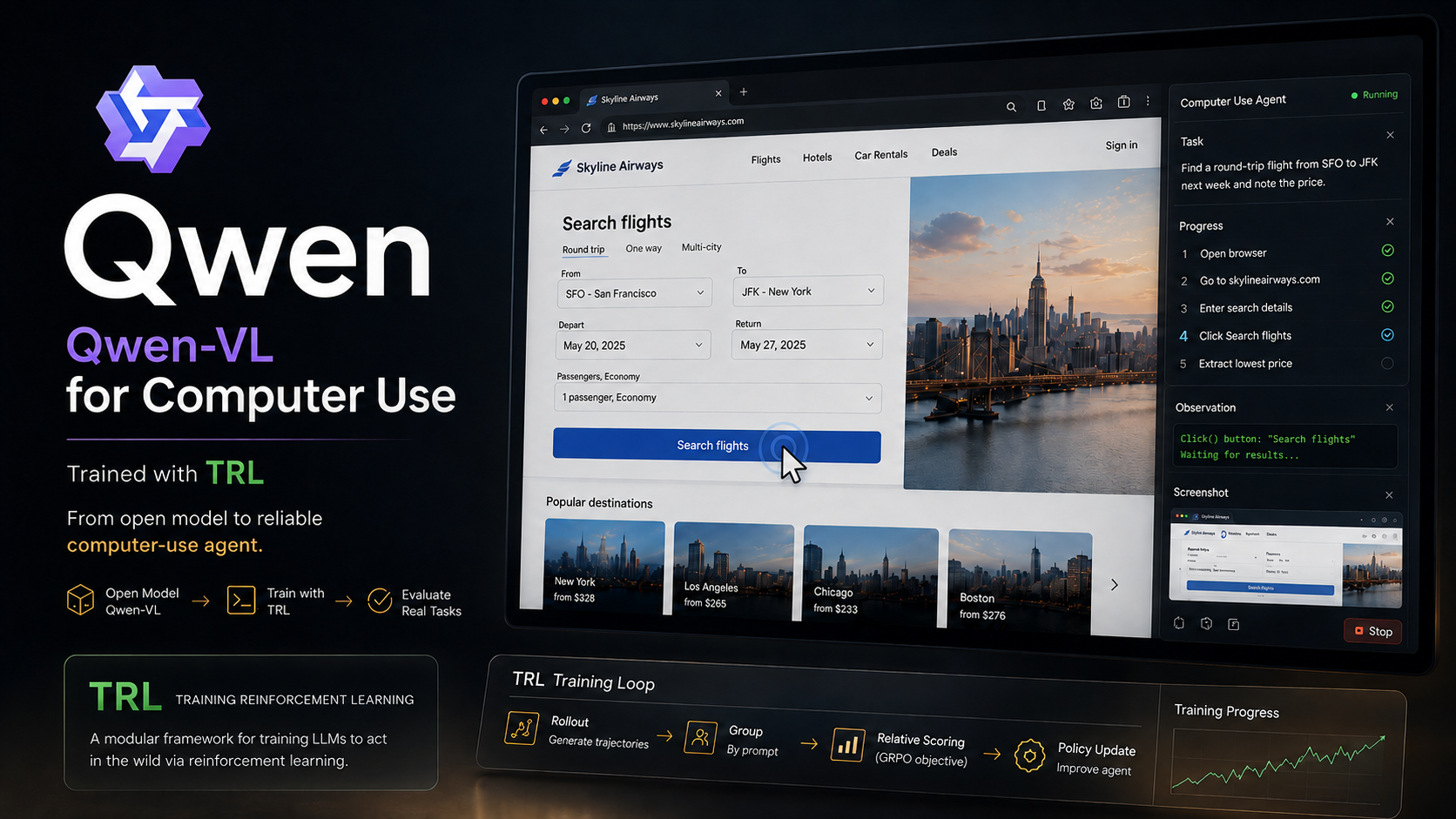
Teaching a 3B VLM to Click: SFT, GRPO, and What Actually Moved the Needle
What it takes to turn an open 3B vision-language model into a GUI grounding agent for about $15: visual grounding, LoRA and QLoRA, and a verifiable-reward GRPO recipe, where SFT does the heavy lifting and RL rewards the whole target, not just its center.
Rotary Positional Encoding: Why Position Is a Rotation
An intuitive, visual guide to Rotary Positional Encoding. Why spinning the query and key vectors beats stamping a position number onto them, why a dot product only ever feels the angle between two vectors, and why that hands you relative position for free. The starting point for understanding how LLMs stretch to long context.
The Evolution of Attention, Part 1: From MHA to Latent Compression
Part 1 of 2. Every attention variant since 2019 fights the same number: KV cache bytes per token. This post traces the first wave of answers, from MHA through MQA and GQA, to DeepSeek-V2’s Multi-head Latent Attention. We end at the 57× cache reduction that comes from caching a low-rank latent and never materializing K or V at inference.
The Platform Around the Agent: What Enterprise Architects Actually Build
Most enterprises have bought an AI coding agent and are stuck. The ones generating real productivity gains didn’t win by picking a better model. They built a platform around the agent. This post walks through the five control-plane responsibilities that separate the 11% of AI-native orgs from the 95% reporting zero ROI, grounded in public deployments from Block, Shopify, Atlassian, Airbnb, and others.
Inside Claude Code: Anatomy of a 512K-Line AI Agent
An interactive technical breakdown of Claude Code’s architecture — from the query loop and five compaction mechanisms to the permission pipeline and feature flags. Based on source code analysis of ~1,884 TypeScript files.
State Space Models and the Mamba Architecture: From First Principles to Mamba-3
NVIDIA’s Nemotron-3-Super, IBM’s Granite, and AI21’s Jamba all ship hybrid SSM-Transformer architectures in production. This post builds State Space Models from scratch, starting with a single differential equation, and works up through HiPPO, S4, and the three generations of Mamba to explain why.
Speculative Speculative Decoding: Eliminating the Last Sequential Bottleneck in LLM Inference
How speculating about speculation itself achieves up to 5x faster LLM inference by eliminating the draft model’s idle time during verification, and the three engineering challenges that make it work.